 360+x : A Panoptic Multi-modal Scene
Understanding
Dataset
360+x : A Panoptic Multi-modal Scene
Understanding
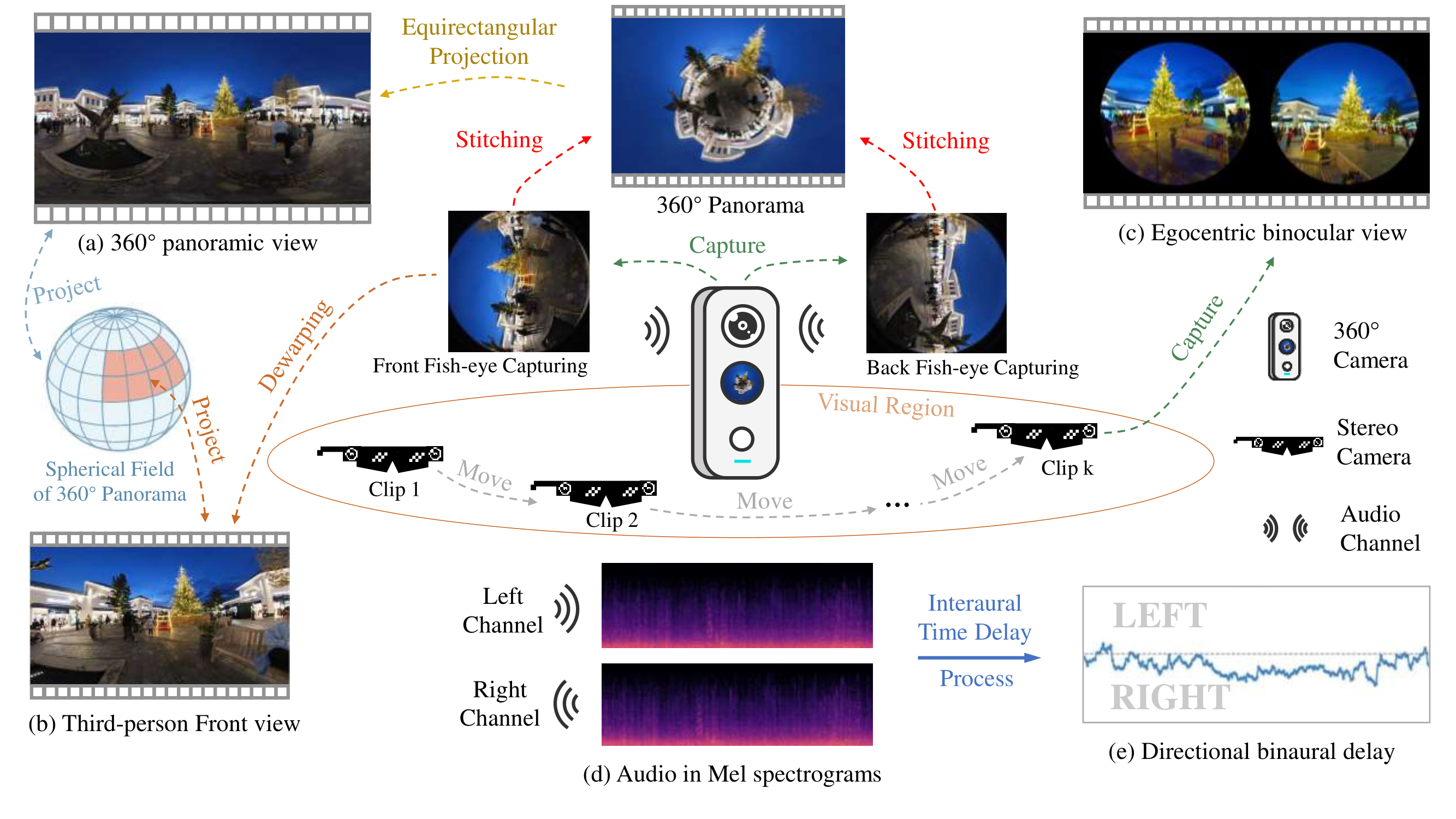
Dataset360+x dataset introduces a unique panoptic perspective to scene understanding, differentiating itself from existing datasets, by offering multiple viewpoints and modalities, captured from a variety of scenes. Our dataset contains:
We have included a Panorama Preview to showcase the equirectangular projection applied to the panoramic video in the Dataset Example. The original spherical state of the video is demonstrated below, providing an initial view of its unaltered form before undergoing the projection process。
The images displayed are downsampled to 2880*1440 due to the limitations of the website display.
We provide more examples of the dataset, including 360° panoramic videos, third-person
front view videos, egocentric monocular videos, egocentric binocular videos, location,
textual scene description and corresponding annotations.
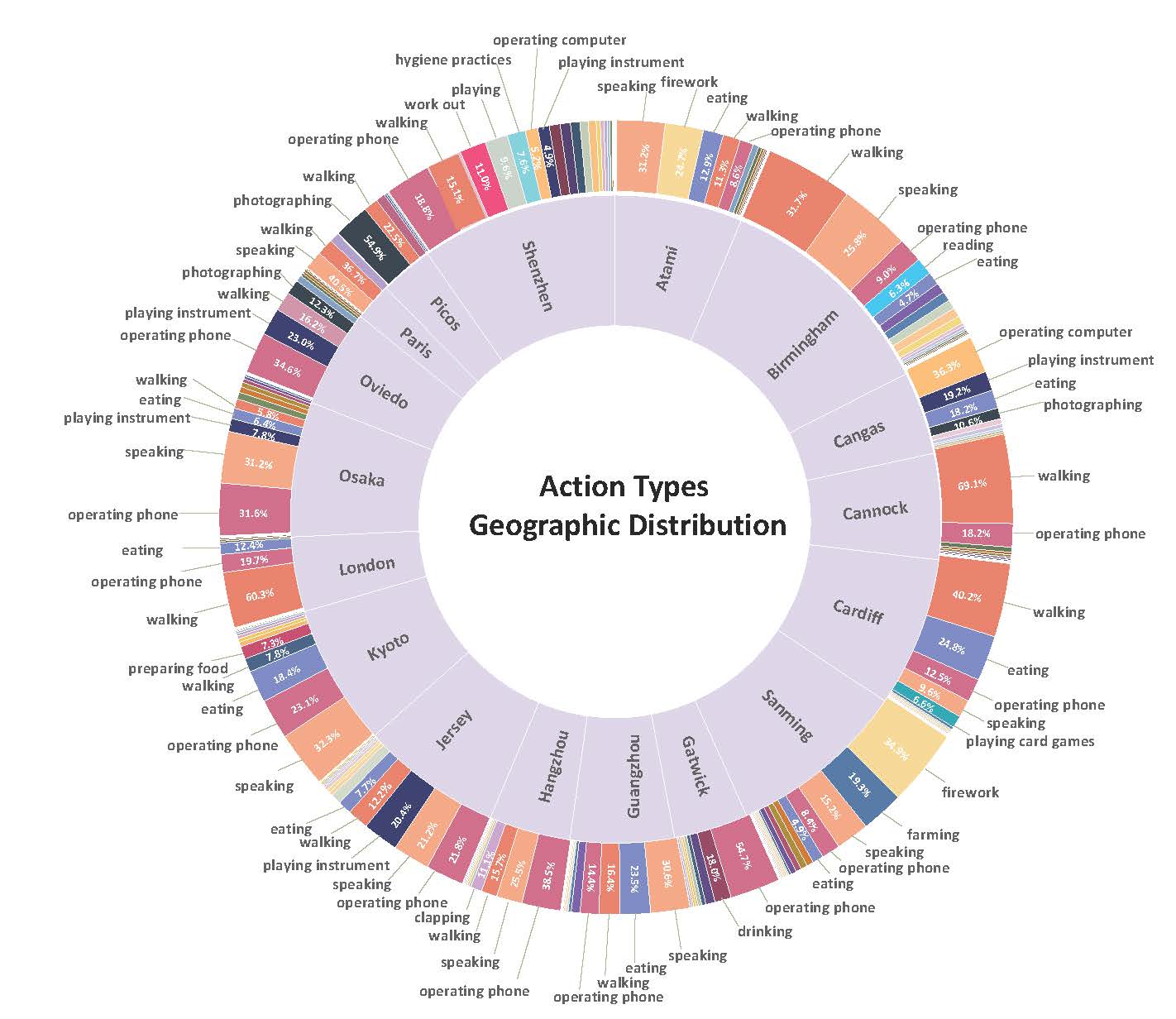
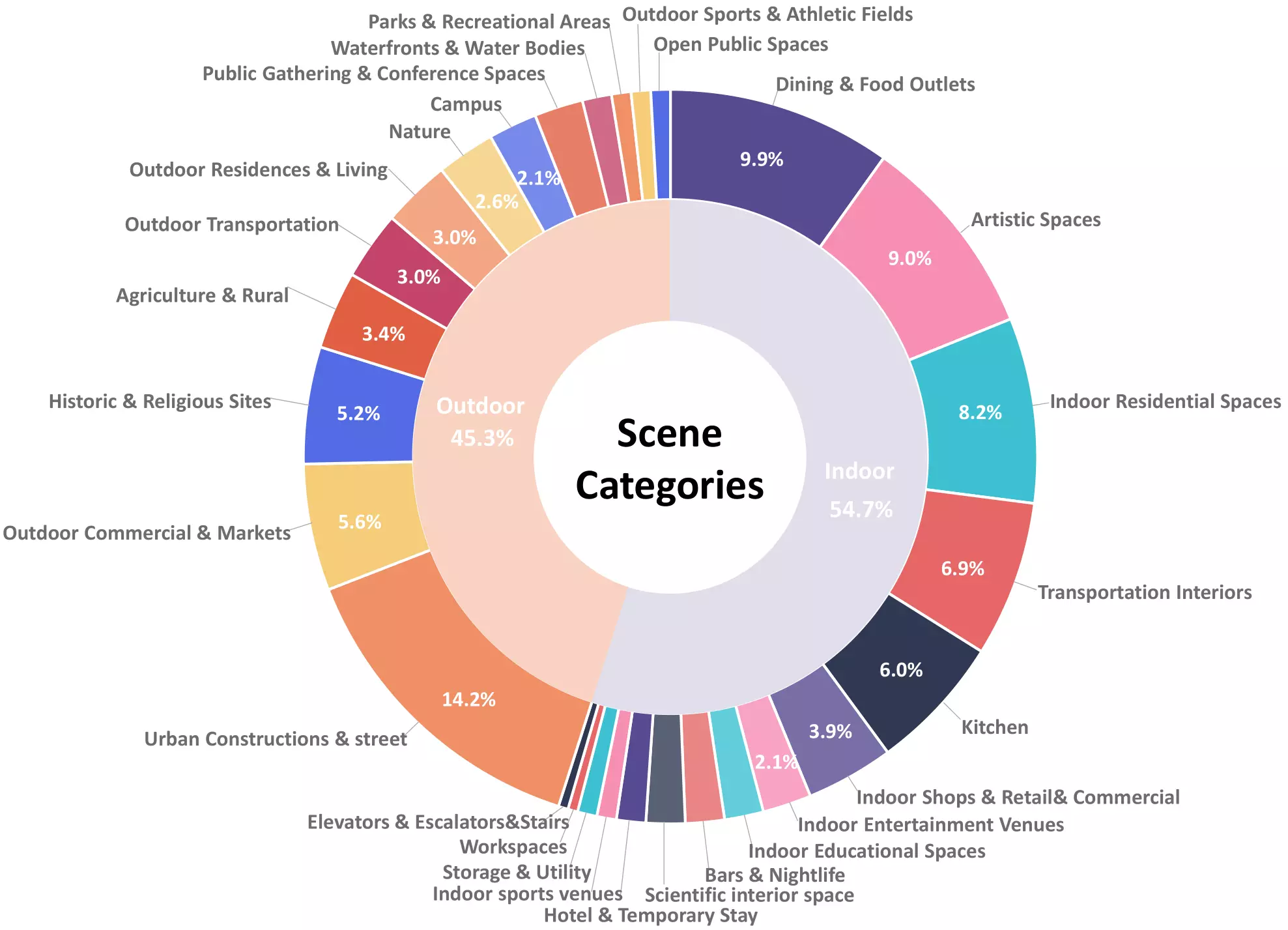
Our dataset comprises 28 scene categories, captured from 15 indoor scenes and 13 outdoor
scenes, totalling 2,152 videos, capturing a wide range of environments. . Among these,
464 videos were captured using the 360 cameras, while the remaining 1,688 were recorded
with the Spectacles cameras. To facilitate analysis and accessibility, these extended
videos have been segmented into 1,380 shorter clips, each spanning approximately 10
seconds. In summary, these clips accumulate to a total duration of approximately 244,000
seconds (around 67.78 hours), and the total number of frames is 8,579K.
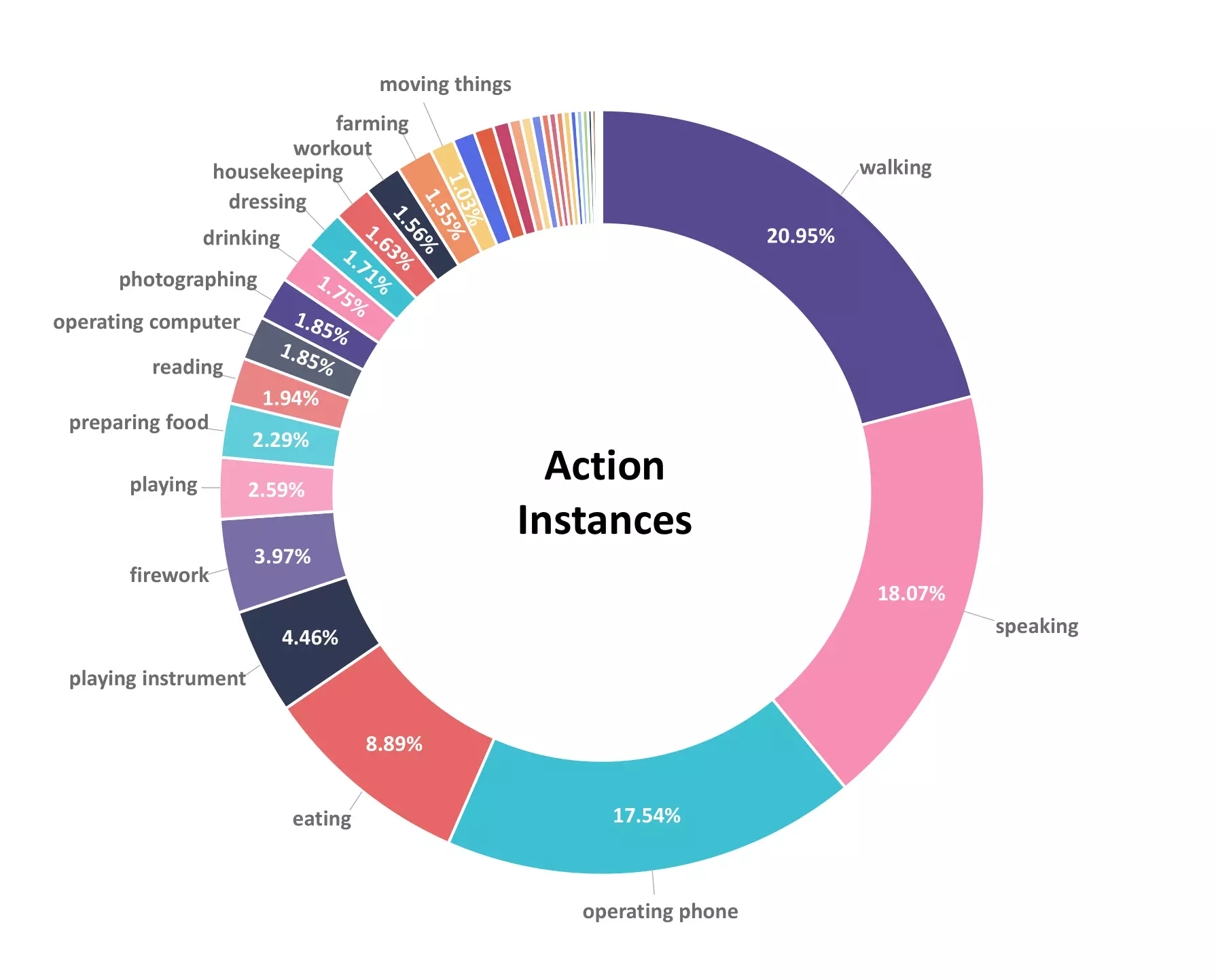
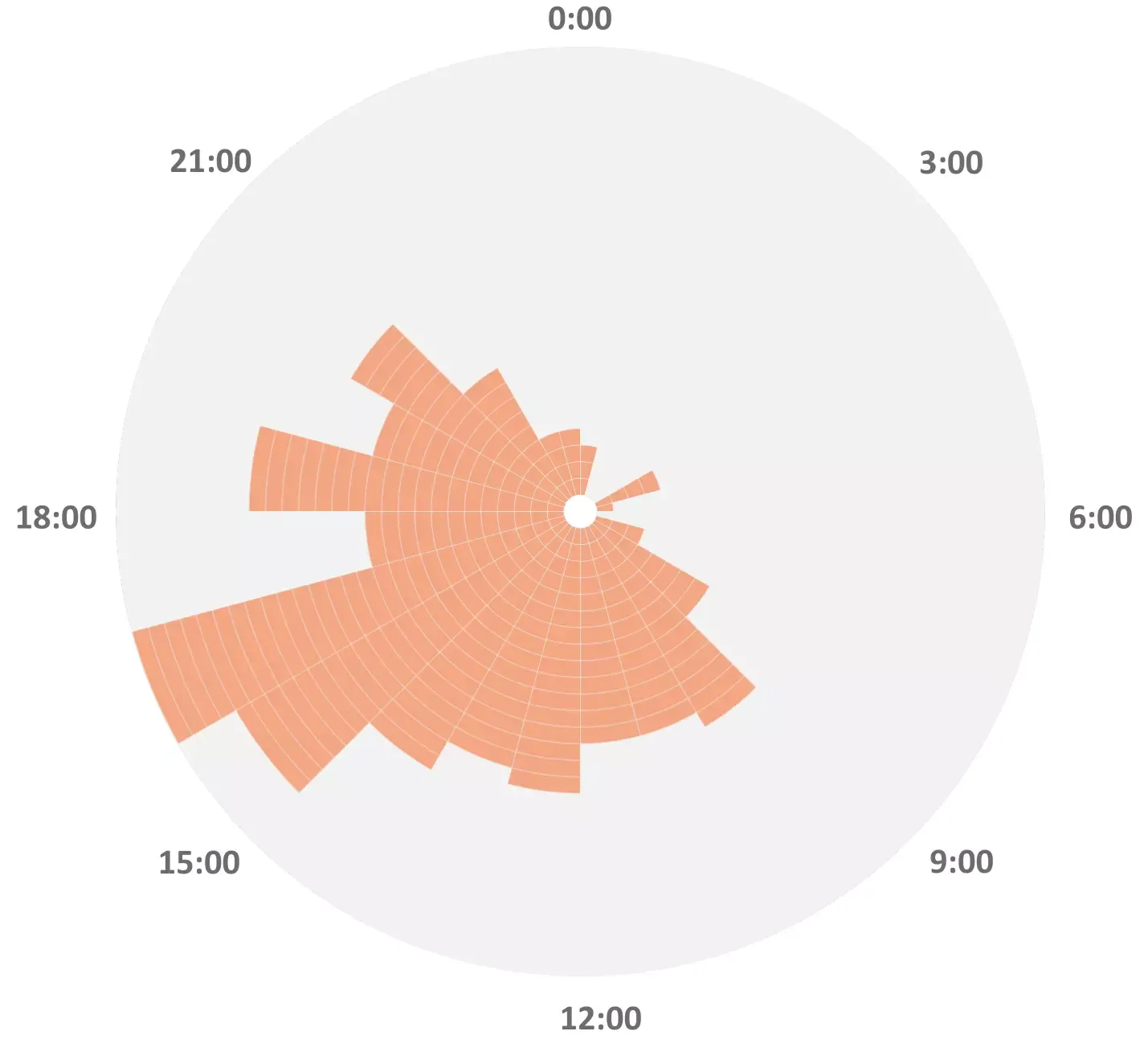
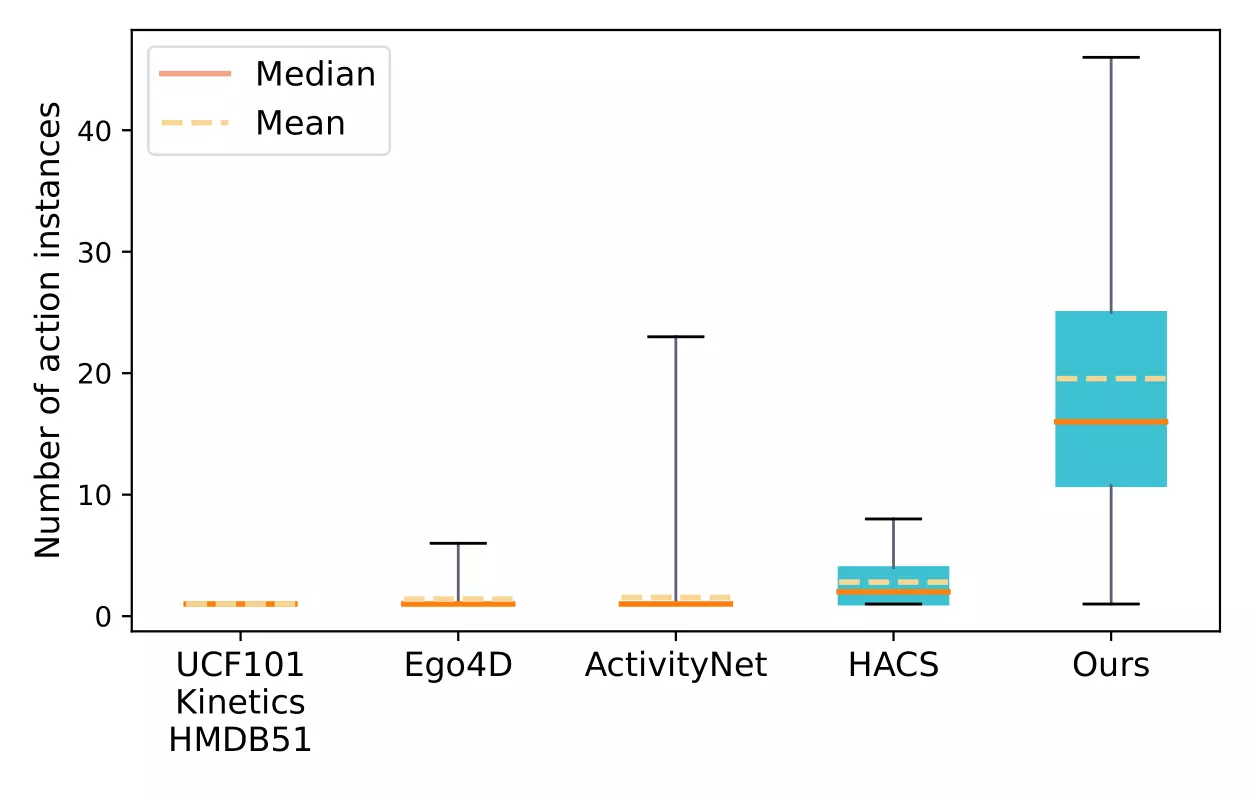
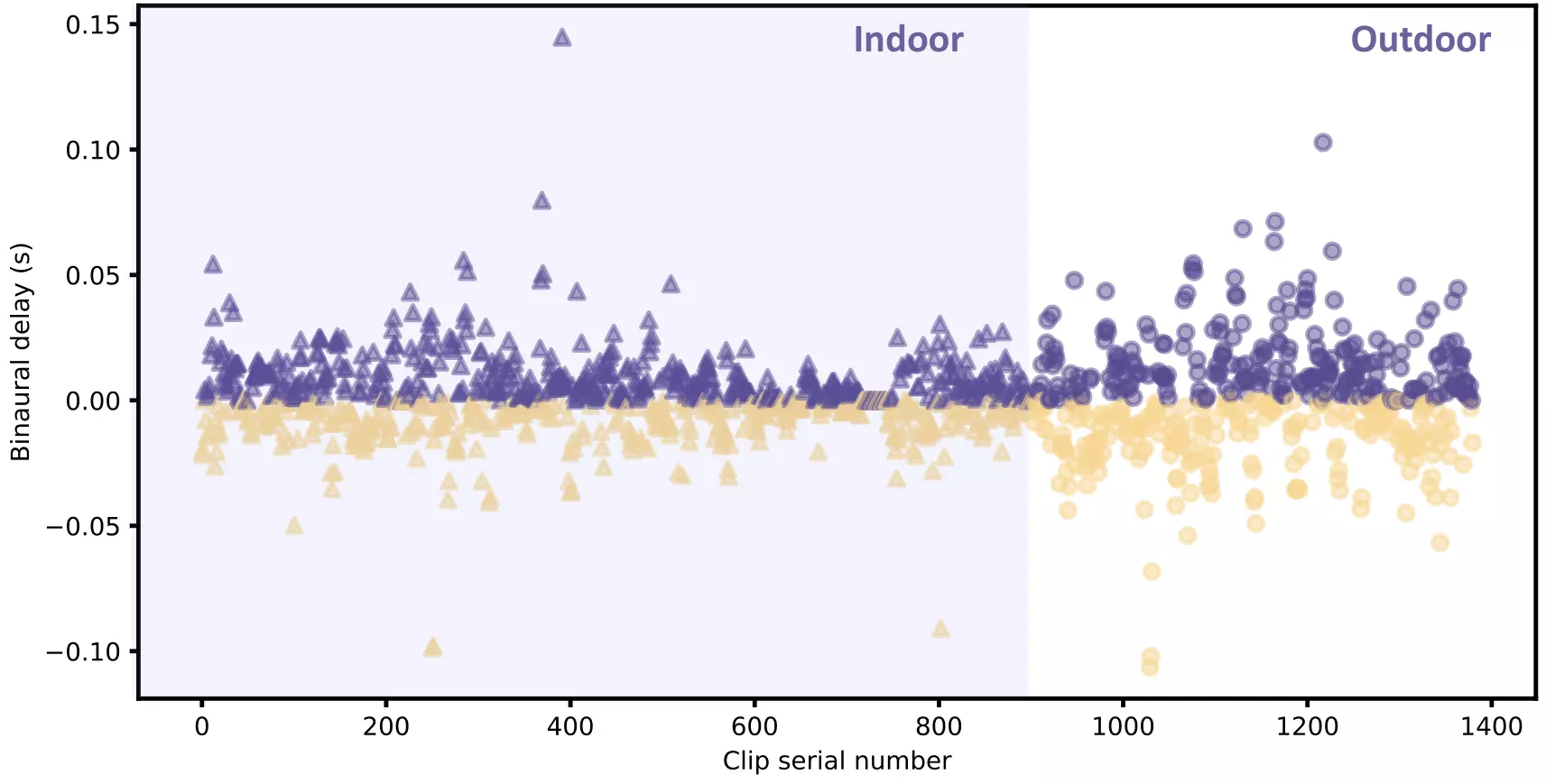
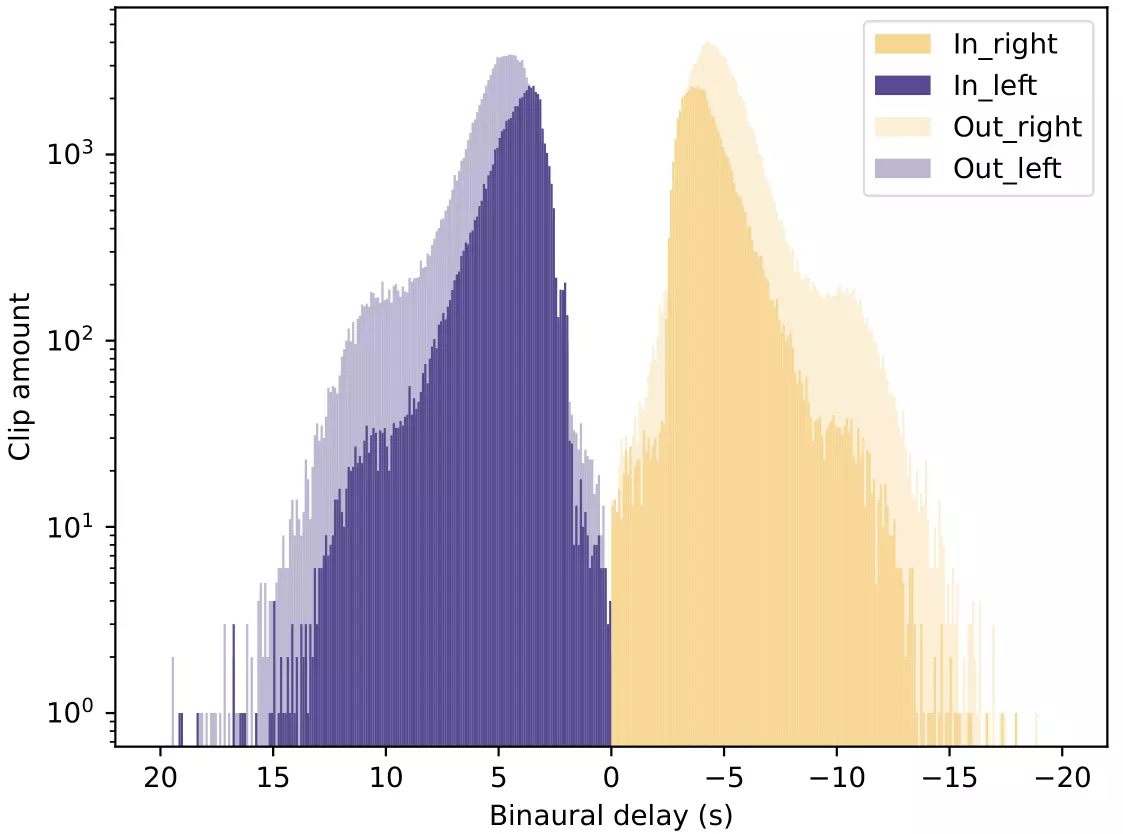
The following figures provide data analysis of the dataset, including the distribution
of
scene categories, the distribution of action instances, the capture time of the day, the
number of action instances per video, the binaural delay per clip and the overall
binaural delay histogram.
Our dataset offers a comprehensive collection of panoramic videos, binocular videos, and third-person videos, each pair of videos accompanied by annotations. Additionally, it includes features extracted using I3D, VGGish, and ResNet-18. Given the high-resolution nature of our dataset (5760x2880 for panoramic, 2432x1216 binocular videos,and 1920x1080 for third-person front view videos), the overall size is considerably large. To accommodate diverse research needs and computational resources, we also provide a lower-resolution version of the dataset (640x320 for panoramic and binocular videos, 569x320 for third-person front view videos) available for download.
Our full dataset, can be accessed by this link 🤗.
For easily accessing, the lower-resolution version can be accessed in this link 🤗
We provide more examples of the dataset, one set for each scene. For website display, each video has been resized to 320p (640*320 for panoramic and binocular videos, 569*320 for third-person front view video). The original video resolution is 5k (5760x2880 for panoramic, 2432x1216 binocular videos,and 1920x1080 for third-person front view videos).
@inproceedings{chen2024x360,
title={360+x: A Panoptic Multi-modal Scene Understanding Dataset},
author={Chen, Hao and Hou, Yuqi and Qu, Chenyuan and Testini, Irene and Hong, Xiaohan and Jiao, Jianbo},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}